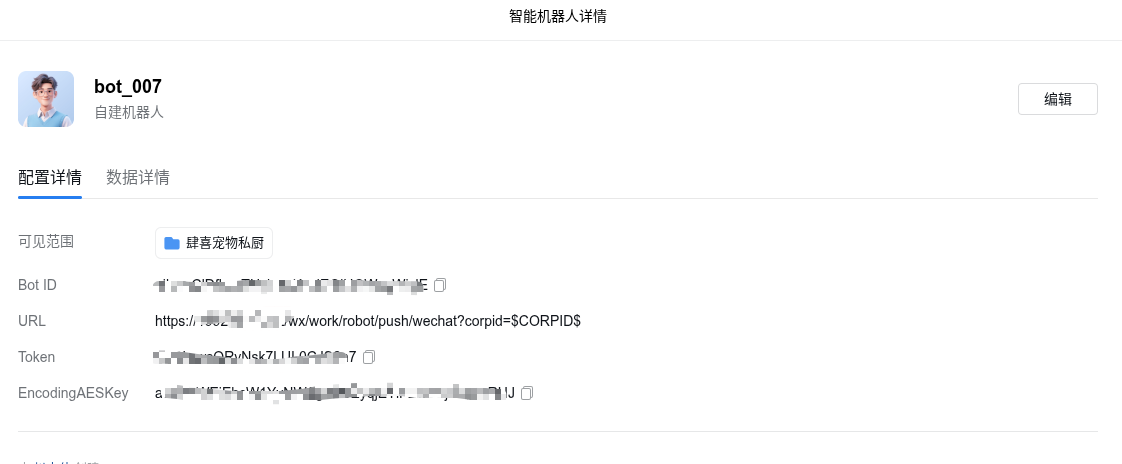
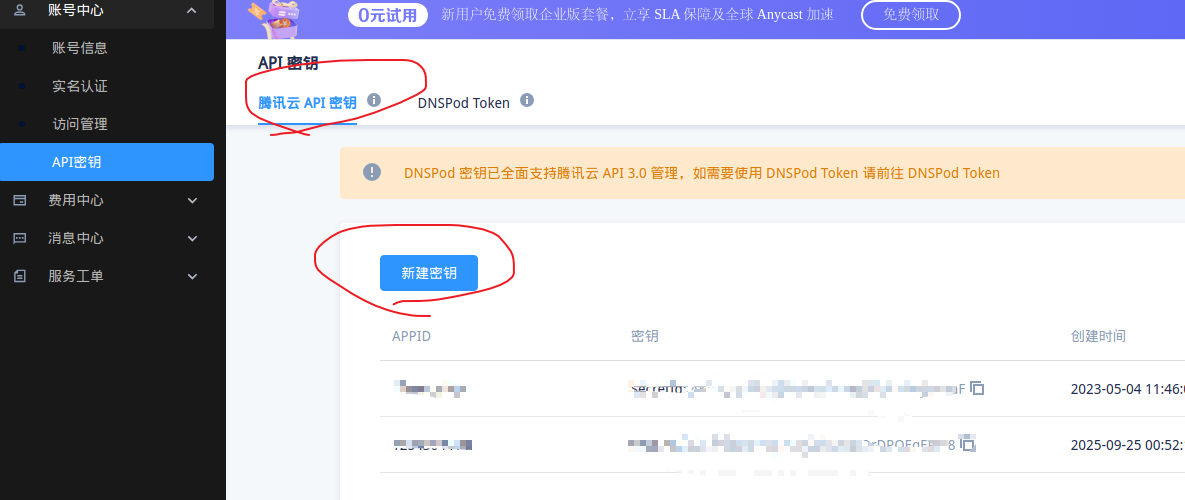
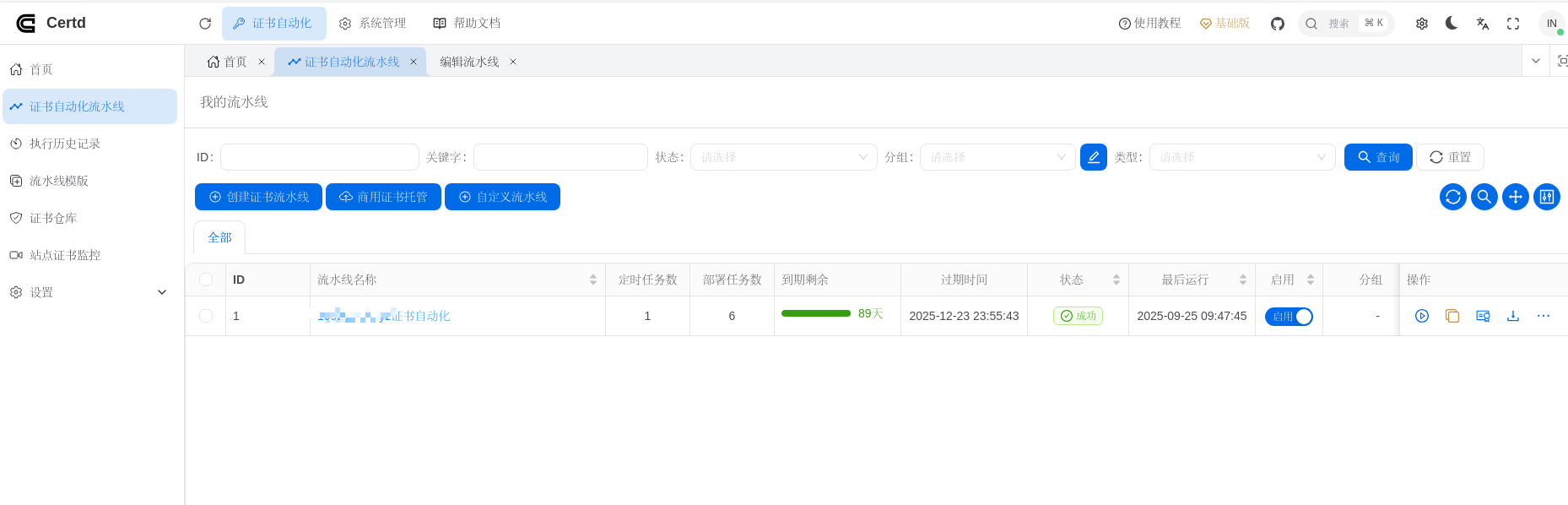
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
@PostMapping("/push/wechat")
public String wechatPost(
@RequestParam("msg_signature") String msgSignature,
@RequestParam("timestamp") String timestamp,
@RequestParam("nonce") String nonce,
@RequestBody RobotData postData) {
log.info("接收消息请求的签名: {}, 时间戳: {}, 随机数: {}", msgSignature, timestamp, nonce);
log.info("接收到的加密消息: {}", JSON.toJSONString(postData));
try {
WXBizJsonMsgCrypt wxcpt = new WXBizJsonMsgCrypt(sToken, sEncodingAESKey, "");
String sMsg = wxcpt.DecryptMsg(msgSignature, timestamp, nonce, JSON.toJSONString(postData));
log.info("消息解密后内容: {}", sMsg);
JSONObject json = new JSONObject(sMsg);
String msgType = json.getString("msgtype");
String chatType = json.getString("chattype");
log.info("消息类型: {}, 聊天类型: {}", msgType, chatType);
if ("text".equals(msgType)) {
JSONObject textObj = json.getJSONObject("text");
String content = textObj.getString("content");
String userId = json.getJSONObject("from").getString("userid");
log.info("用户[{}]在[{}]聊天中发送消息: {}", userId, chatType, content);
String replyMsg = replyMessageStream.reply(json);
log.info("加密前的回复消息: {}", replyMsg);
String encryptMsg = wxcpt.EncryptMsg(replyMsg, timestamp, nonce);
log.info("加密后的回复消息: {}", encryptMsg);
return encryptMsg;
}else if("stream".equals(msgType)){
JSONObject streamObj = json.getJSONObject("stream");
String streamId= streamObj.getString("id");
String poll = streamMapRepository.poll(streamId);
String streamText = streamMapRepository.getStreamText(streamId);
log.info("streamId: {}, pull: {}, streamText: {}", streamId, poll, streamText);
String replyMsg;
if(!StringUtils.hasText(streamText)){
replyMsg = replyMessageStream.buildStreamMessage("你好呀!我是智能机器人,有什么可以帮您的吗? 当前时间是" + new Date(), streamId, true, null);
}else if("messageend".equals(poll)){
replyMsg = replyMessageStream.buildStreamMessage(streamText, streamId, true, null);
streamMapRepository.delete(streamId);
}else{
replyMsg = replyMessageStream.buildStreamMessage(streamText, streamId, false, null);
}
log.info("streamId: {}, 加密前的回复消息: {}", streamId, replyMsg);
String encryptMsg = wxcpt.EncryptMsg(replyMsg, timestamp, nonce);
log.info("streamId: {}, 加密后的回复消息: {}", streamId, encryptMsg);
return encryptMsg;
}
} catch (Exception e) {
log.error("处理消息失败", e);
}
return "success";
}
|